NBA Machine Learning #1 - Introduction to modelling
About series
So I came up with an idea to write series of articles describing how to apply machine learning algorithms on some examples of NBA data. Got to say that plan is quite ambitious - I want to start with machine learning basics, go through some common data problems, required preprocessing tasks and obviously, algorithms. Starting with Linear Regression and hopefully finishing one day with Neural Networks or any other mysterious blackbox. Articles are going to cover both theory and practice (code) and data will be centered around NBA.
Most of the tasks will be done with mlr package since I try to master it and I am looking for motivation. Datasets and scripts will be uploaded on my github, so feel free to use them for own practice!
- 1. Process of building a model
- 2. Linear Regression with mlr package
- 3. Splines, LOESS and GAMs with mlr package
library(tidyverse)
library(broom)
library(mlr)
library(GGally)
library(visdat)
nba <- read_csv("../../data/mlmodels/nba_linear_regression.csv")
glimpse(nba)## Observations: 78,739
## Variables: 13
## $ PTS <int> 23, 30, 22, 41, 20, 8, 33, 33, 28, 9, 15, 24, 21, ...
## $ FG2A <int> 10, 17, 12, 14, 8, 7, 24, 12, 13, 11, 12, 13, 13, ...
## $ FG3A <int> 3, 3, 3, 6, 1, 2, 1, 4, 0, 2, 1, 0, 0, 2, 1, 3, 1,...
## $ FTA <int> 4, 9, 2, 21, 14, 4, 10, 15, 7, 4, 6, 5, 6, 12, 13,...
## $ AST <int> 5, 6, 1, 6, 10, 6, 3, 3, 6, 8, 4, 8, 4, 5, 7, 5, 7...
## $ OREB <int> 0, 2, 2, 1, 2, 0, 2, 4, 1, 0, 2, 0, 2, 1, 6, 0, 0,...
## $ PF <int> 5, 4, 1, 3, 5, 2, 2, 4, 3, 3, 3, 4, 2, 1, 2, 3, 5,...
## $ TOV <int> 5, 4, 4, 5, 2, 1, 0, 6, 4, 3, 6, 1, 1, 0, 1, 6, 2,...
## $ STL <int> 2, 0, 2, 2, 1, 1, 4, 4, 1, 0, 0, 2, 0, 2, 4, 5, 0,...
## $ PACE <dbl> 104.44, 110.01, 94.88, 103.19, 92.42, 93.35, 106.2...
## $ MINS <dbl> 35.0, 33.9, 36.1, 41.6, 34.4, 36.7, 39.9, 34.5, 35...
## $ PLAYER_NAME <chr> "Giannis Antetokounmpo", "Giannis Antetokounmpo", ...
## $ GAME_DATE <date> 2017-02-03, 2017-02-04, 2017-02-08, 2017-02-10, 2...What is machine learning modelling about?
The final result of ML modelling is a function (Phew, just a function, right) or whole bunch of functions providing us a prediction of one variable (called dependent variable), based on the values of other variables (yes, independent ones).
We basically want to predict what will happen, based on our knowledge we got from the history of observations. We are looking for a trends in a data.
I tried my best at making a proper introduction about what is machine learning and I think thousands of people covered it in a better way than this above. I will just move on to not embarass myself.
Define Problem
First step of modelling is to define a problem we want to solve, and how it can be represented by numerical data. Is your dependent variable continous? Is it categorical? If so, how many categories it has?
For my example, it will be predicting how many points will a given player score on given day against specified opponent - so it will be regression problem. General classification of methods looks more or less like:
- supervised learning methods
- regression
- classification
- unsupervised learning methods
- other:
- reinforcement learning
- association rules
Where each one of subcategories consists of lists and lists of different methods and algorithms.
Data preparation
After we collect all desired data, it’s time for data preparation… be patient here, it is actually the longest and not-so-exciting part of a process.
Consists of (mostly visual) data analysis, data cleaning, data cleaning, data cleaning and then feature engineeing. It’s important to remember that we rarely model on raw data. It almost always needs some work to make it useful.
I hope to cover all the steps in distinct articles, but just to list a few:
Visual analysis
univariate analysis
- Plotting distributions of numerical variables (density and histogram plots)
- Barplots to check frequencies of categories
nba %>% ggplot() + geom_density(aes(x = FG2A)) + theme_bw() +
theme(
axis.text.x=element_text(hjust=1,size = 12, face = 'bold'),
axis.text.y=element_text(size = 12, face = 'bold'),
axis.title.y = element_blank()
,panel.grid = element_blank())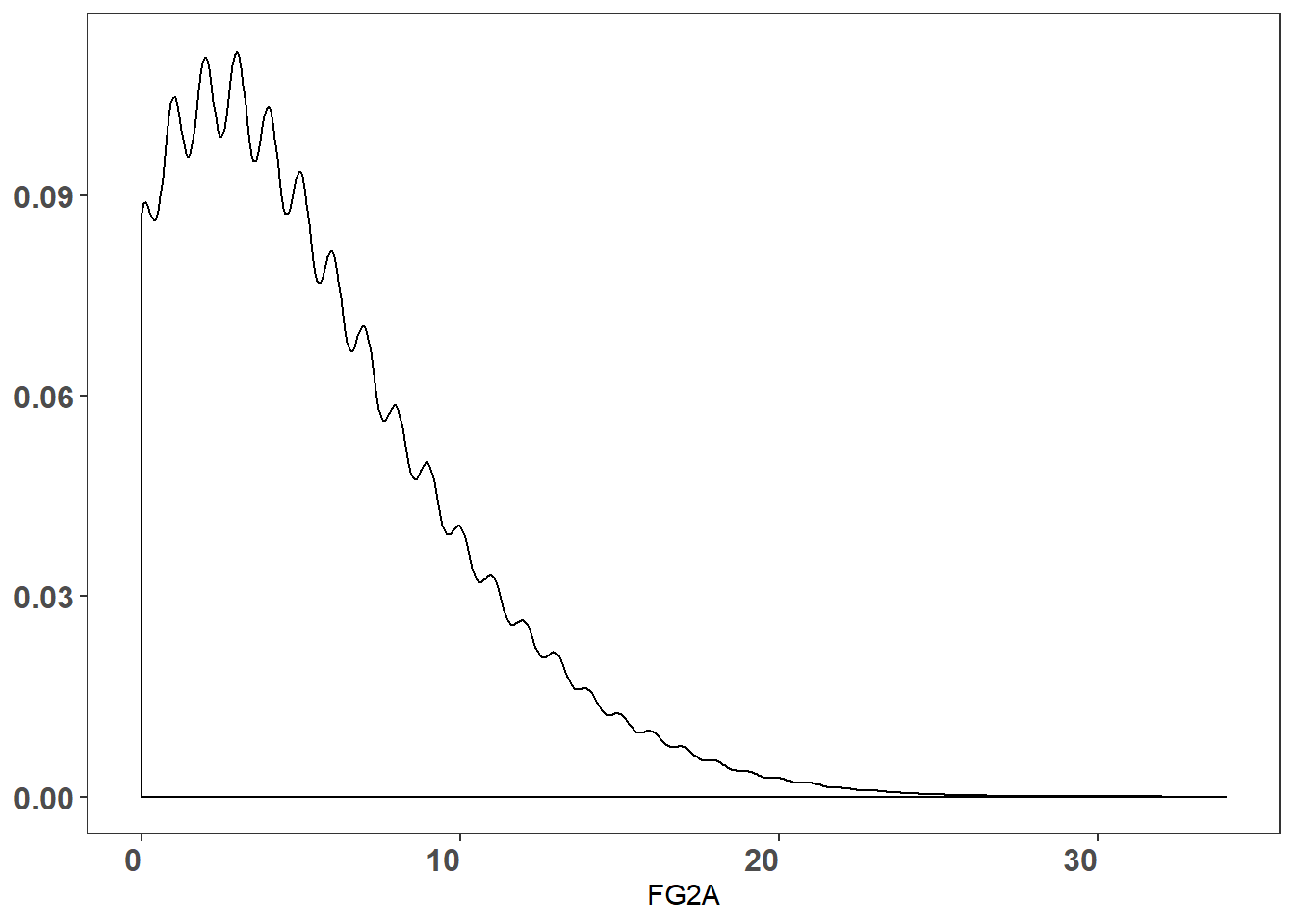
multivariate analysis
- Scatterplots and correlation plots to find dependencies between numerical variables
- Boxplots of categorical variables and dependent variable in order to find useful dummy variables
nba %>%
slice(1:1000) %>%
ggpairs(columns = 2:4) + theme_bw()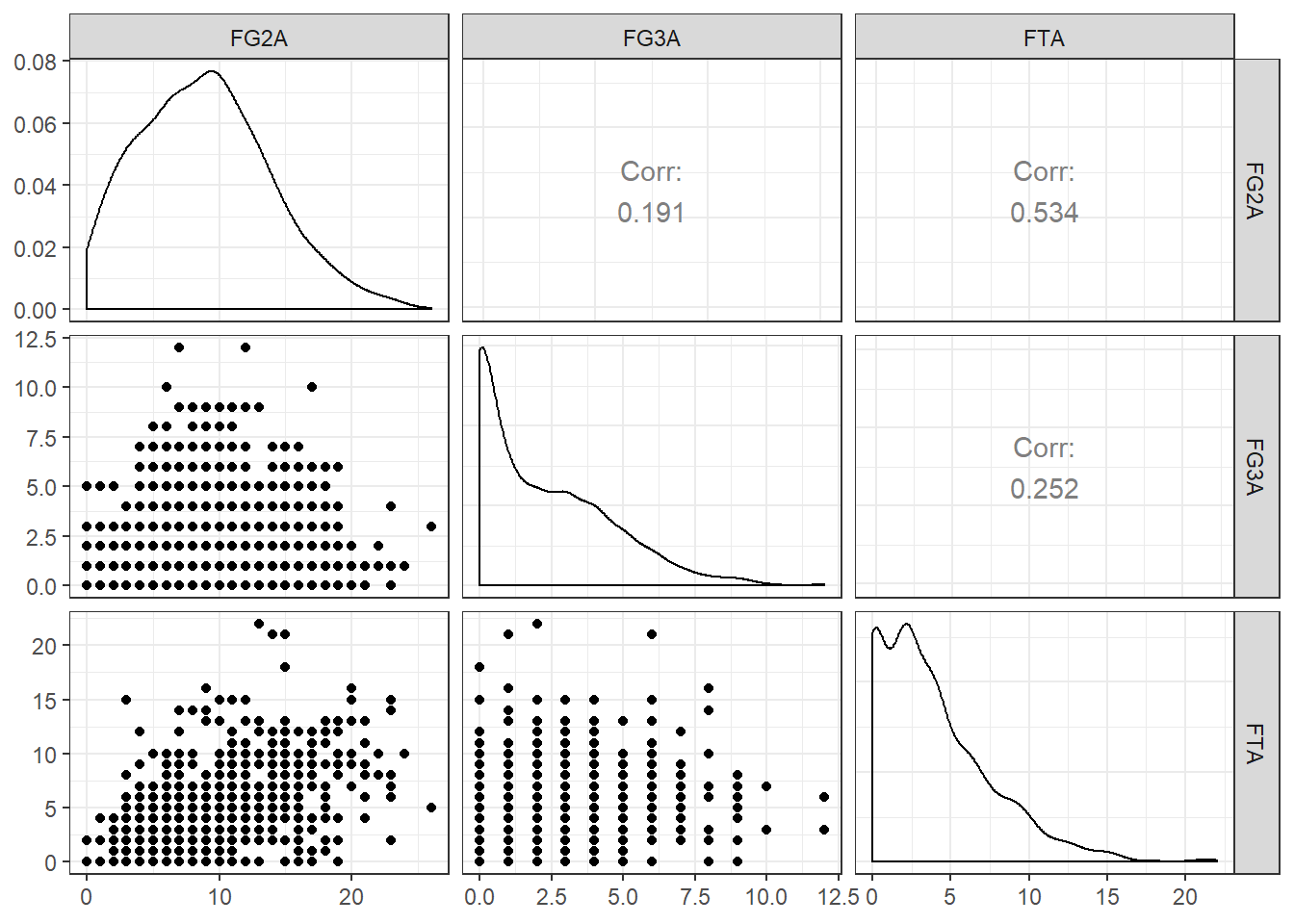
Data cleaning
Do you have a lot of categorical variables? Do you have dates? Sneaky numerical ID columns? Outlying values caused by error? Useless text variables ? Missing values????
Those 1 or 2 annoying observations with missing values that you haven’t spotted…
Most of issues above can be easily spotted during visual analysis, but it’s good to have one more look at the whole dataset:
visdat::vis_dat(nba[1:1000,])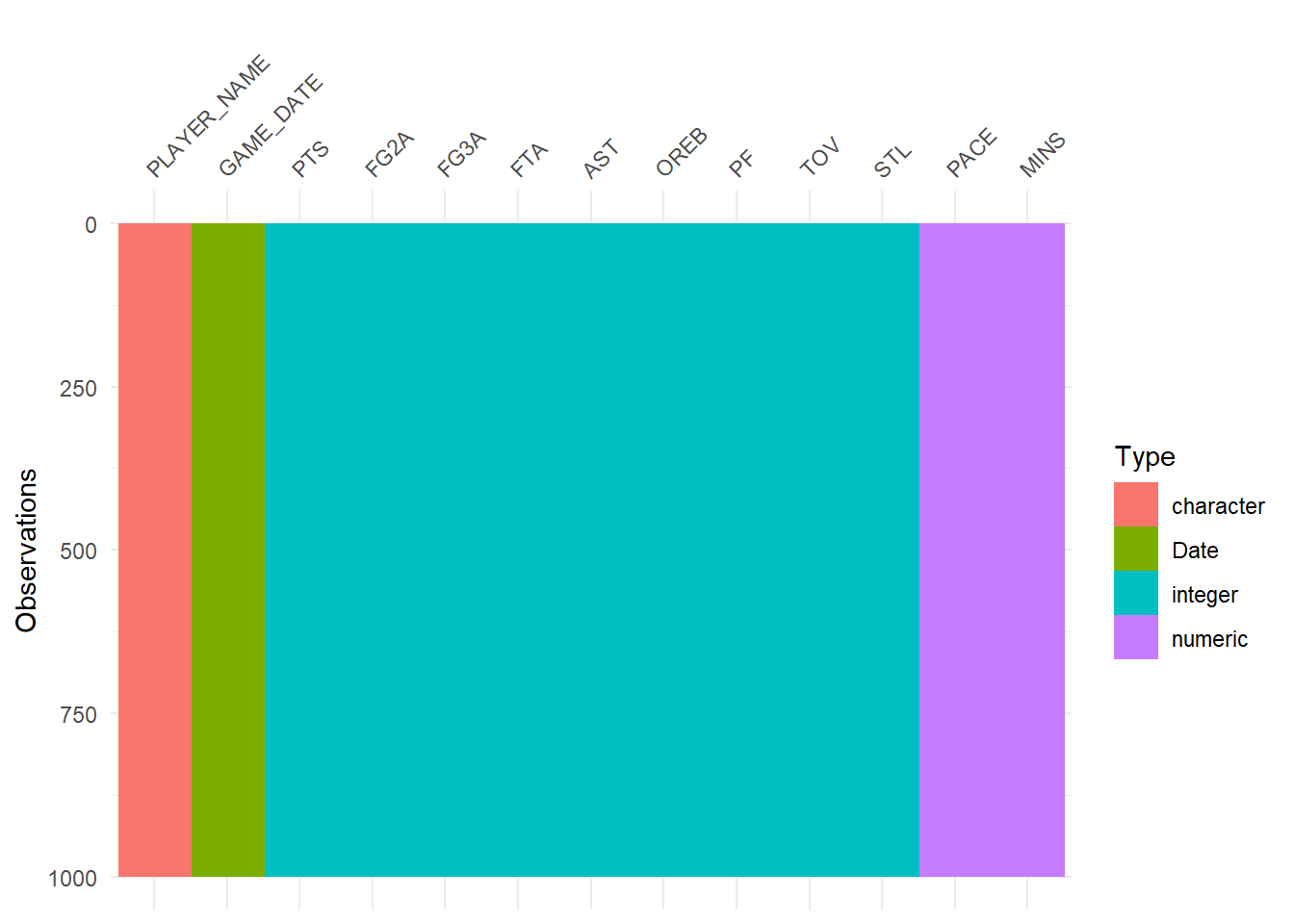
Just to name a few data cleaning tasks (you probably won’t need all of them everytime). There will be article only about those tasks and when to use them.
- normalisation
- standarisation
- scalling
- log-scalling
- binning
- dealing with outliers
- imputing empty values
Feature engineering
Again, this is bread and butter of data science. In the end how you prepare your data is way more important for the overall model score than algorithm that you chose. Winners of every Kaggle competition repeat it regularly that obtaining the right variables was the crucial factor that gave them the advantage.
Proper feature engineering is close to art. You need to use your domai expertise, instincts, data analysis and tries to find what will work. There is no one proper way here.
- how to transform continuous variables
- what’s the best split for categorical variables to create dummy ones
- shall I use dimensionality reduction techniques
- shall I combine some variables
Feature selection
Once again, you can pick variables yourself, but there is high chsnce you will be better off with some standard approaches like using statistical analysis or feature selection algorithms:
- correlation analysis
- permutation tests
- family of entropy and information gain tests
- elastic net approach for regression models
- gridsearch
- stepwise search
Just to name a few. All of them have their pros and cons, and it’s definately good to know them. It’s important to mention that there are methods that are capable of dealing with unimportant variables themselves, but I still wouldn’t recommend leaving them in dataset. This would add unnecessary noise to the data and also slow down the learning process, which is not perfect. Always aim for the best!
Class imbalance
This can be huge if you miss that problem before applying algorithm. If there is large difference (lets say 0.70 to 0.30) between class frequencies in dependent variable, it can lead to false model predictions. As always there are several ways of dealing with it, dependent mostly on number of observations of your training dataset and accordingly number of observations per class.
- If number of observations is huge/sufficient then you can cut the number of observations from major class
- If opposite.. well, then you have to use algorithms to generate new data in order to equalize frequencies. Methods will be covered in further article.
After we got to know our data, managed to process it and select variables we want to use, it’s finally time for some time!
Choose modelling techniques
It’s exciting moment when you are finally ready to apply first algorithm. You can choose from trees, forests, boosting techniques, neural networks, regressions techniques, support vector machines and many many more. Number of possibilities is overwhelming. So, where should you start?
Why one should always start with simpler solutions?
Although I know how tempting it is to just grab tons of variables, perform feature selection, throw them into model bowl and get effortless result, it might be better to start your modelling with some simple approach and then build gradually on top of that.
There are several reasons to do that:
You understand your data better. By picking variables manually (based on domain knowledge/common sense) you easily get to know which features play most important role in defining independent variable.
Model is easier to explain. It’s especially important if you just became data scientist for a company ( :) ) and you need to make other people believe in your theories and analysis. It shows that you know what you are doing. Simple proof of concepts enable non-technical stakeholders to understand the idea behind, understand that it is going in right direction and then they will be eager to wait for more complex solutions.
This argument is more important than you think and way more important than you would like it to be.
- There is a chance that if you pick best features and process them right way, you will receive high quality model with some minimal amount of work. Let’s say we build very simple predictor of Points, using 2 points field goal attempts and three point field goal attempts. (Respectively FG2A and FG3A)
very_simple <- lm(PTS ~ FG2A + FG3A, nba)
broom::glance(very_simple)[c('r.squared','adj.r.squared')]## r.squared adj.r.squared
## 1 0.7711777 0.7711719Model returns R squared of 0.77, which is decent in respect of how much time we spend on building the model (obviously its on training dataset without any validation but still, you get an idea…). It won’t win you a competition on Kaggle, but it will give you solid foundation for further work.
data.frame(real_values = nba$PTS, predictions = very_simple$fitted.values, Game_Player = paste(nba$PLAYER_NAME, nba$GAME_DATE)) %>%
slice(52400:52550) %>%
tidyr::gather(key = 'Variable', value = 'Value', - Game_Player) %>%
ggplot() +
geom_line(aes(x = Game_Player, y = Value, group = Variable, color = Variable), size = 1) + theme_bw() +
theme(
axis.text.x=element_text(angle=45,hjust=1,size = 3, face = 'bold'),
axis.text.y=element_text(size = 12, face = 'bold'),
axis.title = element_blank()
,legend.position='top'
,panel.grid = element_blank())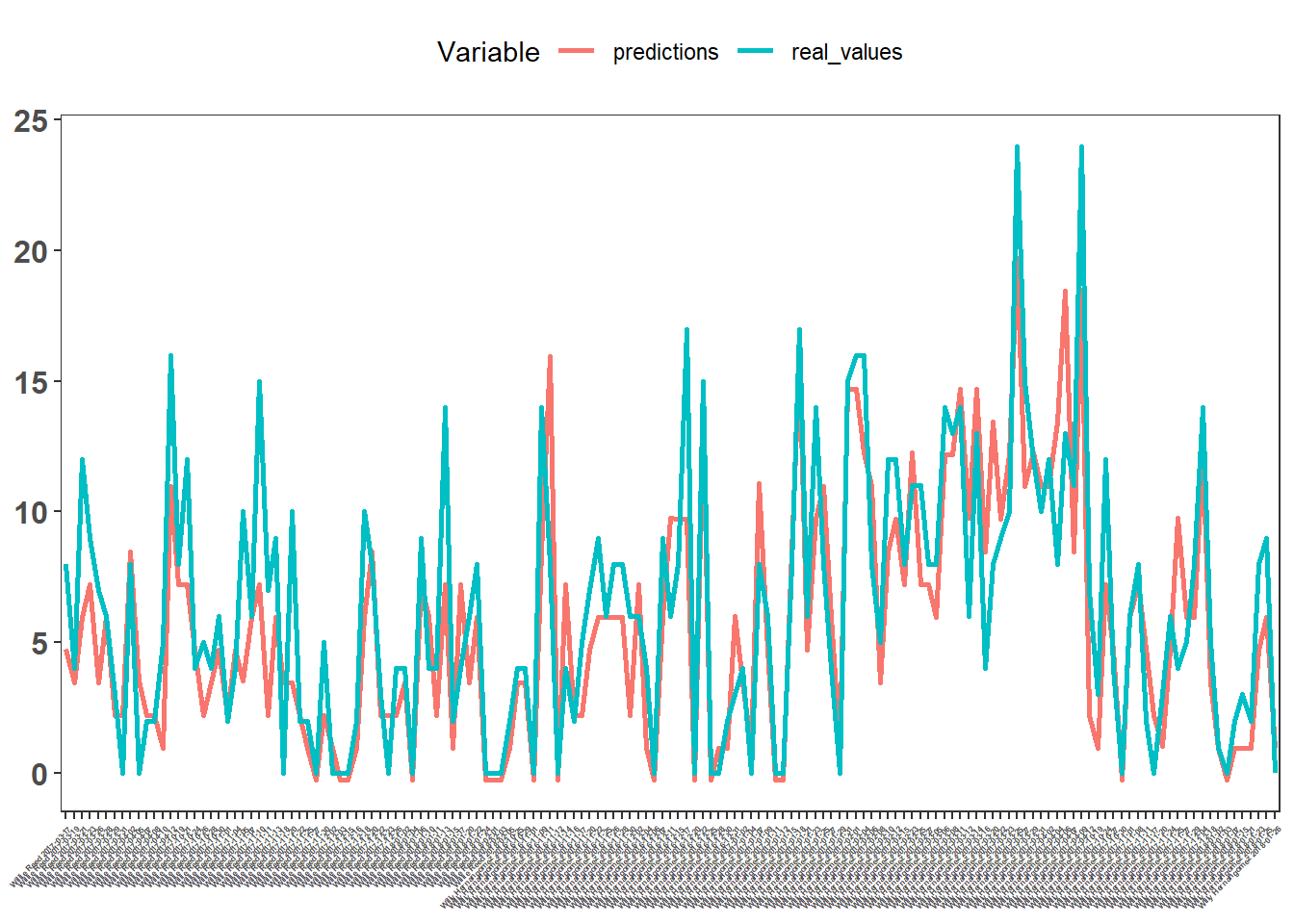
It’s far from perfect, but we got something we can build on.
It has its cons as well:
Yes, it takes time. Especially with large number of variables to consider and when you think about all possible feature engineering methods you can try out. But in the end this is data science job - searching for a real signal somewhere in the data.
It’s totally possible that simple model is not able to cover problem in any way - situation just requires more complex ones (for example necessary variable combinations). Then the simple approach will never give us anything promising. Then well… at least we gain that information.
Bias - Variance tradeoff
Remember that, even though you can build decent model with very simple solution, you should not stop in that point. There is high risk of model being biased. Bias is caused by model making wrong or too simple assumptions about real dependencies occuring in real world.
Imagine if we try to apply linear model on a problem that is highly non-linear. Algorithm will try to fit coefficients to data as best as it can, but even though errors will be minimized, predictions on validation datasets won’t be accurate due to wrong assumptions about reality. That happens because model uses wrong function to describe reality.
What you can do to reduce bias error, is to add more information to the model. Feed it with more observations and more variables so the function will get more complex and will fit better to the data. New learnt function will be definately better reflection of real world.
Unfortunately the more complex the function the higher the variance error becomes. It means that model became so good at fitting training dataset, it is not general enough to predict values for new, never seen before observations. This is called overfitting.
Variance indicates how much the model will change if it trained on new dataset.
During model building you need to remeber about that problem. Your model will perform the best when you find the optimal point between Bias and Variance. Model cannot be too simple because the vias will be very high, in the same time it can’t be overcomplicated, because it will cause high variance and overfitting.
High bias is a problem for parametric algorithms like linear and logistic regression, on the other hand nonparametric models like KNN or Decision Trees have low bias because they don’t assume parametric dependencies. However, those models tend to have high variance. Your goal during building supervised learning model is to achieve low bias and low variance.
Bootstrapping
Bias can be reduced by adding more variables to a model or using nonparametric method. Then we can try to reduce variance by using one of many bootstrap approaches.
- Most common one is using random forest instead of decision trees
- You can also run bagging/ensemble versions of other algorithms
- There are also several versions of Cross-validation that can be used here
- One can stack many different models and then take an average of them to provide final prediction
There are a lot of possibilities…
Model evaluation
After you come up with final model fitted to your training data, it’s time to provide validation dataset so you can check how your algorithm performs on new examples. There are a lot of different metrics that can be used to evaluate model performance, to list few of them:
- Confusion matrics family with ROC curve, AUC and gini index
- Gain and lift chart
- For regression: MAE and RMSE
- For linear regression R squared
And several others. Each of them has its pros and cons and it’s important to be aware of them all, to choose proper one for your case. I am going to cover them during further model building.
Conclusion
What you just read is just short overview of all steps of model building with a lot of lists and little detail. Hopefully I will stick to the plan and I will deliver article of each step described above in the text, providing more context, details and theory.
Next blog post is going to be about simple linear regression model.